
Conversation Testing for AI Agents
.png)

Snir Morlevy

Full Stack Engineer @ Notch
Snir Morlevy is a full-stack engineer at Notch, where he helps build the core platform for creating agents and managing their deployment lifecycle. He works across the stack to turn complex infrastructure needs into reliable, scalable product experiences.
Stay ahead in support AI
Get our newest articles and field notes on autonomous support.
Oops! Something went wrong while submitting the form.
Share








April 30, 2026
How Notch Keeps Quality Consistent at Scale
At Notch, we build and deploy AI agents that resolve operational workflows end-to-end for insurance carriers and financial services firms, where consistency, compliance, and reliability are not optional.
Getting an AI agent into production in a regulated environment is hard. Keeping it reliable, compliant, and consistent at scale is even harder. The reason is simple: LLMs are not deterministic. With traditional software, the same input should give you the same output every time. With LLMs, small changes in prompts, policies, model versions, conversatio context, or even the same model in diffrent ienferance provider can lead to different outcomes. Sometimes those changes are improvements, sometimes they quietly introduce new problems.
“Practice does not make perfect. Only perfect practice makes perfect.”
That is why we built conversation testing into the Notch dashboard, we wanted a way to test AI conversations with more structure, consistency, and a lot more visibility, not just checking whether an answer looks fine in isolation, but validating whether an agent behaves the way it should across full conversations, versions, and real-world interactions.
Over the course of this blog we will write tests for a specific flow: “Customer said hello”, and see as the number of tests grows with our needs and coverage.
Let’s start with the first and simplest test:

Why conversation testing matters more with LLMs
Traditional software usually breaks loudly. LLM systems often break quietly, they do not always crash, they drift. Tone changes, policies get applied inconsistently, handoffs are missed, or a conversation that used to resolve smoothly starts going off track a few turns in. In regulated environments, this isn’t just a quality issue, it’s a compliance risk, a small drift can mean giving incorrect financial guidance, exposing restricted data, or failing to escalate a high-risk interaction.
That is what makes QA for conversational AI fundamentally different. You cannot rely on a few spot checks and assume the system is solid, testing one prompt and getting one good answer tells you very little about how the agent will behave in production. What you need is a repeatable way to stress the system across many scenarios and see how it performs when conversations unfold like they do with real customers, and that is the role conversation tests play for us.
Conversation testing is also how we validate that our guardrails actually work in practice. Our agents are built on a multi-layer guardrail architecture, from LLM-level constraints to business logic and operational limits, and each of those layers needs to be tested across real scenarios.
Let’s add to our tests, now that we know that even slight changes in tone can cause the entire conversation to shift, we will make sure that we stay on track:

Test full conversations, not just single messages
One of the biggest mistakes in AI QA is testing isolated responses instead of full conversations. A single response can look perfectly fine on its own and still push the interaction in the wrong direction later, whether by setting the wrong expectation, missing context, or introducing friction that only becomes obvious a few turns later.
For example, a conversation might start as a simple inquiry about coverage, but evolve into a request that requires identity verification or escalation. A correct first response is not enough if the agent later exposes restricted information or fails to enforce policy constraints.
Real customer interactions are multi-turn, messy, and full of edge cases, so the tests have to reflect that. In Notch, conversation testing is built around complete scenarios rather than one-off prompts, giving teams a much more realistic way to validate quality from the first customer message through to resolution.
By now you know that testing single messages is not a reliable way to ensure consistency and compliance over an entire conversation, let's make modifications to our tests to accommodate this:

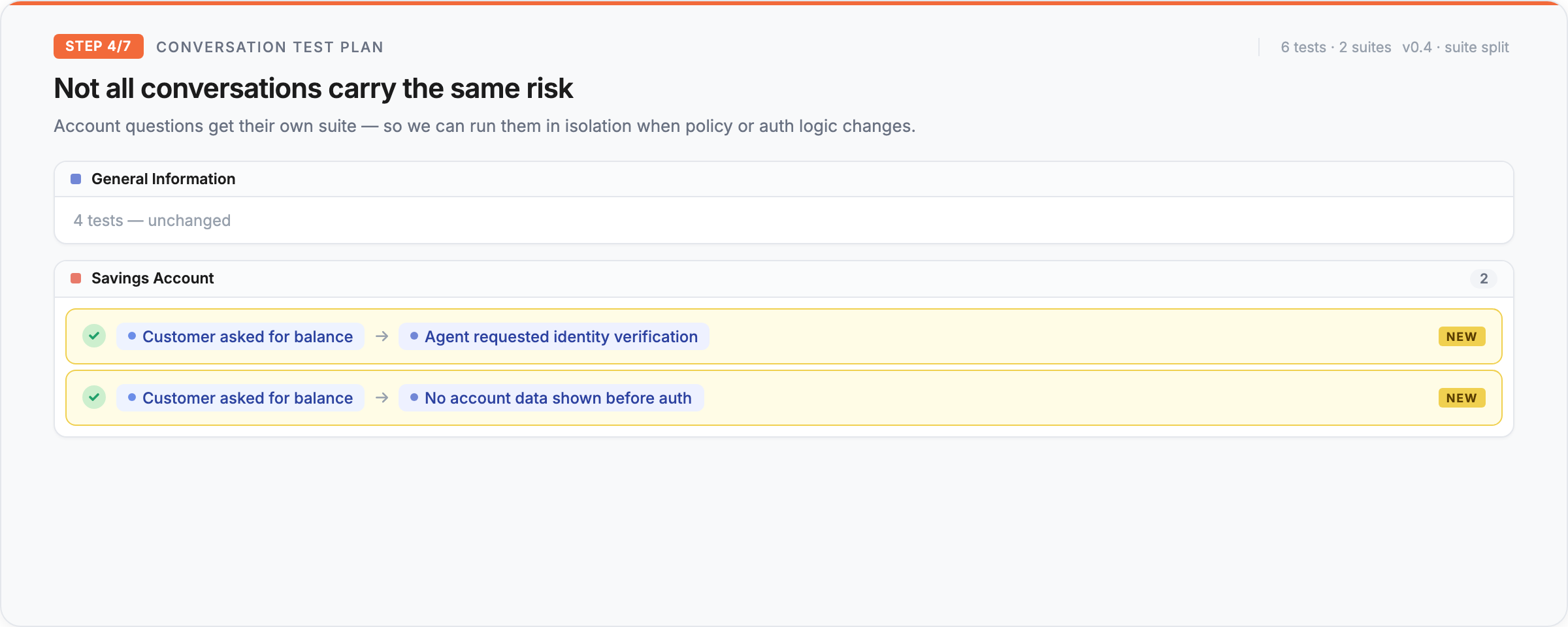
Different test suites for different scenarios
Not all conversations carry the same risk, and they should not all be tested the same way. Some flows are simple and repetitive, while others are sensitive, tone-critical, or important enough that even a rare failure matters, and that is why teams can create different test suites for different scenarios.
Instead of throwing everything into one giant bucket, you can organize tests around how your agent is actually used in production: by intent, flow, edge case, use case, policy area, or customer journey. In a non-deterministic system, that kind of coverage matters even more, because if behavior can shift in subtle ways, you want clear visibility into the scenarios that matter most.
Now let’s assume that instead of general information, the customer asked us about a specific service that the company offers, this would necessitate a different test suite that runs when updating different policies:
Quality is more than correctness
A response can be technically correct and still be a bad customer experience. It might take too long, sound robotic, miss the tone you want, or follow policy in a way that feels unnatural. The response must also be compliant with internal policies and external regulations. That is why our conversation tests do not stop at “did the agent answer correctly?”.
Teams can enforce strict performance metrics like generation time and tone of voice alongside the expected conversational outcome. That creates a much better definition of quality for customer-facing AI, because customers do not experience your agent as a set of separate dimensions, they experience the conversation as one thing, and if the tone is wrong or the response is too slow, the interaction still feels broken.
To remain compliant and responsive over time, we should add our additional metrics to our test suites:

Run tests at scale and see exactly where they failed
Manual testing falls apart quickly with conversational AI. There are too many flows, edge cases, and subtle failure modes for spot checks to be meaningful. In a non-deterministic system, scale matters even more.
With Notch, teams can run lots of tests and test suites in parallel, but speed is only half the story, the other half is visibility. When a test fails, you can see the outcome and exactly where it failed in the conversation, not just that something went wrong, but which turn caused the problem and how the interaction drifted. That makes debugging much more practical, especially in LLM systems where failures are rarely binary and usually happen inside the flow.

Simulate real customer conversations using real customer data
The best test is the one that looks closest to production, and that is why Notch lets teams simulate and view conversations as if they were real customer interactions, using real customer data from real conversations.
This matters because synthetic prompts are useful, but they are usually much cleaner than reality. Real customers are inconsistent, indirect, emotional, and often incomplete in the way they communicate, so if you are working with non-deterministic AI, you need to test against that reality rather than idealized examples, because that is where quality actually gets proven.
This is especially important in regulated industries, where real conversations often include partial information, ambiguous intent, or attempts to bypass safeguards.
Compare different versions of your agent properly
With LLM-based products, changes are rarely isolated. A model swap, prompt tweak, policy update, retrieval change, or tool adjustment can improve one flow and make another worse, because behavior is interconnected, so when you ship a new version, you need a reliable way to compare it against the old one.
The conversation tests feature lets teams run the same test suites across different versions of the agent, making it much easier to see whether a new version is actually better or just different. Instead of relying on a few manual checks and gut feel, teams can compare versions against the same conversation scenarios and make decisions based on evidence.
Historic results are how you spot drift
With LLM systems, one good run does not mean much, what matters is whether the agent stays good over time. That is where historic test results become really valuable, because they let teams look back at previous runs, compare performance across versions, and spot trends that would be invisible in a single test session.
This is especially important for non-deterministic systems, where regressions can appear gradually rather than all at once. Quality is not a one-time event, it is something you monitor.
Now that we have our basic test plan, all that's left is to run it periodically and automatically with every change. When your test run history looks like this, you’re not guessing anymore, you know your agent is stable, consistent, and ready for production.

AI-versus-AI Testing Across Every Environment and Channel
Agents for testing Agents. Today, Notch also supports AI-versus-AI testing, where a customer QA agent tests the production agent across environments and channels with a clear scenario goal, such as “I want to cancel my credit card because it was lost.” The customer QA agent behaves like a real customer: it follows the script, asks follow-up questions, shares or withholds information, reacts naturally, and pushes the conversation until the flow reaches its expected outcome. Once the interaction ends, the test evaluates whether both AI agents completed their goals: whether the customer QA agent reached the intended scenario status, whether the production agent followed policy, required authentication when needed, handled the request correctly, stayed within business limitations, and responded with the right tone and timing. An AI judge then reviews the full conversation and determines whether the call went as planned, turning quality assurance into a realistic, automated role-play that can run continuously across chat, voice, staging, production, and every other environment where the agent operates.
What’s next
The next step is not just better tests. It is building systems that can continuously test themselves.
If AI agents are going to take on more of the work, they cannot depend on manual QA cycles that happen after the fact. Every policy change, code change, workflow update, and product decision should automatically create the conversations needed to validate it. Every new behavior should come with coverage. Every regression should be caught before it reaches production.
This is the loop we need to close: agents that improve, systems that generate the right tests, and infrastructure that validates every change before it affects a real customer. In that world, conversation testing is not a phase in deployment. It becomes the safety layer that allows AI agents to evolve continuously, under the guardrails, permissions, and escalation paths we define.
That future still needs humans. It needs exceptional engineers, product thinkers, and system builders who can design the environment AI agents will live inside. At Notch, we are building that infrastructure for reliable AI in regulated industries, and we’re hiring a top-notch team to help shape it.
Key Takeaways
Key Takeaways
FAQs
Got Questions? We’ve Got Answers
No items found.
.png)



.png)
AUTONOMOUS ORGANIZATION
Autonomous AI for operations leaders ready to turn complexity into advantage.
Deployed in weeks. Autonomous in months. Compounding for years.
Book a demo
Deliver better outcomes across every metric that matters
Get more done across every channel, system, and workflow.
Decouple revenue growth from operational cost.
Every action governed, traceable, and audit-ready.